For many embedded C developers the most predominate and questionable feature of C++ is the class. The concern is that classes are complex and therefore will introduce code bloat and increase runtimes in systems where timing is critical. Those concerns implicate C++ as not suitable for embedded systems. I’ll bravely assert up front that these concerns are unfounded.
When [Bjarne Stroustrup] created C++ he built it upon C to continue that language’s heritage of performance. Additionally, he added features in a way that if you don’t use them, you don’t pay for them.
Data Hiding
Prior to the object-oriented paradigm shift in, roughly, the early 90s, structured programming was the technique to use. One of the principles that came with it was data or information hiding.
A good example for C programmers is the FILE pointer (FILE*). The only thing you know about a FILE* is that it points to a data structure somewhere in a library. You can open, read, write, and otherwise manipulate a FILE* through a set of functions. The actual data about the file you’re working with is hidden. In a sense, this is a step toward object- oriented programming. The FILE* points to the object, a struct, and the functions are the class methods that operate on the object, or instance.
[Stroustrup] took C’s struct and extended it to create a class based form of object-orientation. He might have taken another approach since there are other forms of object- orientation. For instance, if you work heavily with JavaScript you’re doing prototype object- oriented development.
Let’s look at classes and their non-existent code bloat in this article. We’ll encounter some other features of C++ along the way. I’m compiling with C++11 as implemented by the GNU Project GCC compilers to obtain the latest features of the language. I chose it because it’s the compiler used by the Arduino family of boards and can be used by the Raspberry Pi. It is often available for other processors, making it well suited for the hacker community.
I’ll be compiling the code for both an Uno and a Due board to illustrate that the type of processor is irrelevant. The Uno uses an ATmega328P 8-bit processor and the Due an ATSAM3X8E ARM Cortex-M3 CPU 3- bit processor, so there is quite a difference between them.
Declaring Classes
Classes are user defined types (UDTs). In C++ classes, structs, unions, and enums are all UDTs. A UDT is the equal of the data types you are familiar with in C: integer, char, float, double, etc. UDTs act just like built in data types in C++ statements: initialization, function calls, function return values. Operations on UDTs mimic the built in operations: arithmetic operations, logical operations. It was a design goal for C++ that UDTs and regular data types operate with no noticeable differences.
[Elliot] discussed ring buffers in a recent article, Embed with Elliot: Going ‘Round with Circular Buffer, so I borrowed his C code with a few modifications and created this equivalent C++ class:
namespace had {
using uint8_t = unsigned char;
const uint8_t bufferSize = 16;
class RingBuffer {
uint8_t data[bufferSize];
uint8_t newest_index;
uint8_t oldest_index;
public:
enum BufferStatus {
OK, EMPTY, FULL
};
RingBuffer();
BufferStatus bufferWrite(const uint8_t byte);
enum BufferStatus bufferRead(uint8_t& byte);
};
}
The first new C++ features in the code are the namespace and using keywords. They aren’t specific to classes so let me defer explaining them for a few paragraphs.
A class declaration begins with the keyword class followed by a name, just as C creates structs. In fact, struct could be used here instead of class. The difference between the two is struct, by default, provides public access to data and member functions while a class restricts access by default.
The next three lines declare data members of the class exactly as you would do with a struct in C. Since this is a class the members are private and cannot be accessed from outside the class. This is how C++ supports and stringently enforces data hiding.
The public keyword says the following lines are openly available. These can be accessed outside the class. You can also use private in the same way as public to make the following lines not accessible. A third access keyword is protected but it is used for class inheritance, a more advanced discussion, and we’ll ignore it for now. These access control keywords can be mixed as you wish in a class.
Next an enum is specified. Here it works just like a C enum.
The next line declares the class constructor. The purpose of a constructor is, in my vernacular, to make the class sane when it is created. It should set all the variables in the class to default starting values and contain code that sets up the class for proper operation. That may mean allocating dynamic memory for the class to use. For instance, RingBuffer could be setup to handle buffers of a chosen length instead of a globally defined fixed length. The length would be passed as an argument to the constructor and used to size the dynamically allocate memory.
The next two lines are member functions for writing and reading bytes of data to and from the buffer, the array data, in the class. There is no difference between these declarations and similar ones in C, except for one more C++ feature that is again not specific to classes, the & in the parameter declaration for bufferRead(uint8_t& byte). The & indicates the parameter is passed by reference. We’ll add that to the list of additional features to discuss below.
These are the basics for classes as UDTs. There are a lot of details about their design and implementation but those are beyond the scope of this article. A key point is that a class encapsulates within it all the capabilities you would provide for a data structure in C.
Using the Class
The code using RingBuffer is just a skeleton to illustrate how classes are used:
had::RingBuffer r_buffer;
void setup() {
}
void loop() {
uint8_t tempCharStorage;
// Fill the buffer
for (int i = 0; r_buffer.bufferWrite('A' + i) == had::RingBuffer::OK; i++) {
}
// Read the buffer
while (r_buffer.bufferRead(tempCharStorage) == had::RingBuffer::OK) {
}
}
Line 1 of the code is the definition of a RingBuffer variable. The had:: is a scoping operation that tells the compiler to use the RingBuffer declared in the had namespace. Similarly, on lines 9 and 12, the enums OK are scoped in had.
Calls to class member functions use the same dot-notation that C uses for accessing members of structs. The calls are just r_buffer.bufferWrite and r_buffer.bufferRead. If you want to call a class member function from a pointer to a variable the arrow-notation is used. Except for that adaptation, member functions calls are the same as C calls.
Behind the scenes, the compiler is passing r_buffer as a hidden parameter to the member functions. It is passed as a pointer and within the functions is accessed by the name this. You can access the member data using the this pointer like this->newest_index but it is typically unnecessary. There are situations where it is used.
C Version of Code
For completeness let’s look at the C version of the code. It’s remarkably similar. Here are the declarations:
typedef unsigned char uint8_t;
enum BufferStatus {BUFFER_OK, BUFFER_EMPTY, BUFFER_FULL};
#define BUFFER_SIZE 16
struct LifoBuffer {
uint8_t data[BUFFER_SIZE];
uint8_t newest_index;
uint8_t oldest_index;
};
void initBuffer(struct LifoBuffer* buffer);
enum BufferStatus bufferWrite(struct LifoBuffer* buffer, uint8_t byte);
enum BufferStatus bufferRead(struct LifoBuffer* buffer, uint8_t *byte);
We’ve got a typedef instead of the using, and a define instead of a const. After that LifoBuffer defines the same data, and the function declarations are about the same. The initBuffer serves basically the same purpose as the constructor. And we see a pointer instead of a reference.
One difference is the explicit passing of the pointer to the data structure. That is the same as the hidden this that C++ passes to member functions.
The calling routines look very similar also:
struct LifoBuffer buffer;
void setup() {
initBuffer(&buffer);
}
void loop() {
uint8_t tempCharStorage;
// Fill the buffer
uint8_t i = 0;
for (; bufferWrite(&buffer, 'A' + i) == BUFFER_OK; i++) {
}
// Read the buffer
while (bufferRead(&buffer, &tempCharStorage) == BUFFER_OK) {
}
}
Source Files
Sorry to disappoint, but I’m not going to post the complete source files. You wouldn’t see any more difference than in the calling routines. But here is a snippet from each to satisfy your curiosity. I’ll show the bufferRead function so you can see how the reference parameter is handled. First the C++:
RingBuffer::BufferStatus RingBuffer::bufferRead(uint8_t byte) {
if (newest_index == oldest_index) {
return EMPTY;
}
byte = data[oldest_index];
oldest_index = nextIndex(oldest_index);
return OK;
}
Now the C version:
enum BufferStatus bufferRead(struct LifoBuffer* buffer, uint8_t *byte) {
if (buffer->newest_index == buffer->;oldest_index) {
return BUFFER_EMPTY;
}
*byte = buffer->data[buffer>oldest_index];
buffer->oldest_index = nextIndex(buffer->oldest_index);
return BUFFER_OK;
}
The major difference is the C++ version looks cleaner without the pointer dereferencing operators needed in C to access the buffer data structure. The parameter byte, the reference, also is accessed more easily. The main drawback with the C++ version is the need for the scoping operator, the ::, necessary to tell the compiler the functions and enums are part of the RingBuffer class.
There are two advantages to having the BufferStatus enum within the class RingBuffer that make using the scoping operator worth the effort. First, the enum names are shortened by having the buffer_ prefix removed. The scoping operator tells the developer and the compiler when these status values are valid. Second, it avoids name conflicts that can cause confusion. You might have other classes that use a status of OK or FAIL. Those may not use the same underlying values. If those classes are buried in a library you have no way of changing their values. One may say OK‘s value is 1, and the other 4. The scoping operator sorts out that problem, and the compiler enforces it by refusing to allow an enum from one class to be used with another.
Additional C++ Features
Let’s back up and look at the additional features of C++ we’ve encountered: namespaces, using, and references.
Namespaces
I didn’t intend to introduce namespaces in this article but the need to use them came up when I compiled the C++ code for the Due. I’d been compiling for the Uno without any problems; but when I switched to the Due, the compiler generated errors that it took me a few moments to understand: my RingBuffer class name was clashing with a RingBuffer class name used by the Due for serial communications.
Name clashes amongst libraries and user code is exactly the reason for having namespaces. I could have changed the name of my class to FifoBuffer which is actually a better name because it describes the usage while RingBuffer describes the implementation. Another name, more Computer Science oriented, is queue. I didn’t use it because the C++ standard library implementation of a FIFO is named queue. I left it at RingBuffer so I could discuss namespaces.
Creating a namespace is easy:
namespace <name> {
// some code }
So is using one:
using namespace <name> {
// some code
}
I wrapped the entire header file, RingBuffer.h, and the source file, RingBuffer.cpp, in the namespace had, for HackADay.
In the Application.cpp file where I used the RingBuffer class I needed to qualify the constructor and the uses of the BufferStatus enums with the had namespace so the compiler knew I wanted them, not the ones from the library.
Aliases: Using and References
Both the using keyword and references create aliases. The ability to create aliases is a general feature of C++ that was extended and improved in C++11. For the most part, aliases allow the use of simpler names to refer to more complex expressions.
Using
The using keyword creates an alias for a complex data type. Here the type unsigned char is given the alias uint8_t. This usage replaces the use of typedef, which still available to not break legacy code. If this simple example doesn’t impress you how about having an alias to simplify const unsigned long int* const or a pointer to a function with a large number of parameters.
Here are the two lines of code from above:
using uint8_t = unsigned char;
const uint8_t bufferSize = 16;
Notice how the statements are similar. The second line creates the variable bufferSize and initializes it to the value 16. The first line creates the name uint8_t and sets it to the data type unsigned char. This parallelism of the constructs is why using was introduced. A big effort in C++11 was the standardizing of expression forms along these lines.
References
References are a feature of C++ that appear in many places. Since this is not a tutorial on C++ I won’t elaborate beyond their use as a function parameter.
Function arguments can be passed in multiple ways. One way is by value. This is the usual way in C/C++ for arguments: a copy of the value from the argument variable is passed. Any operations within the function modify the local value but have no affect on the argument variable.
C/C++ can also pass arguments by pointer, which is a form of reference passing. Operations affect the original value. We know that pointers are dangerous so C++ wanted to minimize their use.
A reference is an alias of the argument variable. Just as with a pointer the address of the argument variable is passed. The big difference is you cannot manipulate this address since it is not exposed as with a pointer. The original value of the argument variable is affected by any operations in the function.
Cost of Classes
I teased above about showing that there is no cost to using classes. This is 99.9999%, or something around there, true. In this article I’m only going to look at code size because someone looking at C++ classes and seeing their additional complexity expects there has to be a cost.
I used Eclipse with the Arduino plugin mentioned in Code Craft: Using Eclipse For Arduino Development to compile the code for the Arduino Uno and Due. Here are the results:
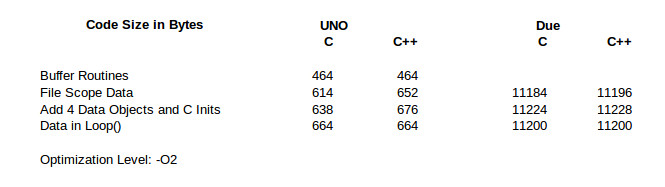
Clearly there is no major code bloat when using C++ on either processor. Let’s walk through the table first for the Uno and then come back to look at the Due results.
The line Buffer Routines is the code size for just the FIFO buffer code and empty Arduino setup() and loop() routines. I did this only for the Uno because I was too lazy to go back and strip the Due version down to the minimum. As we’ll see, it doesn’t matter.
The next line, File Scope Data, has the definitions of the data structures at file scope in the Application source file. The C++ code is 38 bytes larger because the class constructor is called. In order to call the constructor additional code is executed before main() is called. In any C/C++ application there is system specific initialization code executed to setup the application. C++ just adds a little more to call all the file scope constructors.
The next line shows that it is the initialization code as I suggested. An additional 4 data structures were added to both programs, with calls to their initialization inserted in the C version. The difference between the two versions remains at 38. That is a fixed overhead you’ll see on an Uno for using C++.
In the final line, I moved the definition of the data structure, and initialization for the C version, into loop(). That takes them out of file scope which means the C++ special initialization code is not needed. Now both versions have the same code size.
So, at least for the Uno, I rest my case. C++ classes do not cause code bloat.
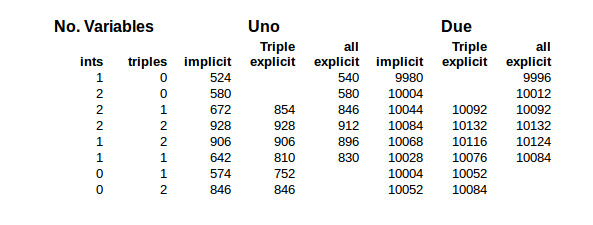
The results for the Due are identical except for the case with multiple data structures at file scope. There is a 12 byte overhead for having a single data structure at file scope. Okay,I assumed that’s the C++ pre-main() initialization code. But that overhead reduced to only 4 bytes when the additional 3 data structures were added. What? This deserved additional investigation.
I went back to having one data structure at file scope then added more one at a time, recording the increase in code size. The C version alternately increases by 8 and 16 bytes. The C++ version increases by 16 bytes for the second data structure and by 8 bytes for each one after that. I could generate some guesses on this but frankly it’s not worth the effort since these differences are small.
As with the Uno, the final line demonstrates there is no code bloat. This is when the data structures and initialization are moved to within loop().
There it is. No code bloat from using classes in embedded systems.
Wrap Up
I just scratched the surface explaining classes in this article. I wanted to provide enough explanation so C developers would understand the concepts sufficiently to accept classes are not going to increase code size. More details would just be confusing, and there are a lot more details. I also don’t want to play language lawyer so the presentation is pragmatic, not pedantic.
Software development is a complex process. A continuing goal for language developers has been to provide a tool that is efficient to use both in writing and executing code. C++ classes not only are efficient in code size but they help avoid common errors made during development. One measure of development is that rate at which bugs are fixed. Even better is preventing bugs from occurring.
The class constructor is a bug preventor. When you instantiate a class the constructor is going to be called to initialize the variable. Consider the situation with the C code where I created FifoBuffer a number of times. For each of those variables I needed to add the call to init(). It’s very easy to forget that initialization, especially if you create the variable in a file other than where the initialization is to take place, like the setup() in an Arduino application.
The Embedding C++ Project
Over at Hackaday.io, I’ve created an Embedding C++ project. The project will maintain a list of these articles in the project description as a form of Table of Contents. Each article will have a project log entry for additional discussion. Those interested can delve deeper into the topics, raise questions, and share additional findings.
The project also will serve as a place for supplementary material from myself or collaborators. For instance, someone might want to take the code and report the results for other Arduino boards or even other embedded systems. Stop by and see what’s happening.
Filed under:
Arduino Hacks,
Hackaday Columns,
Raspberry Pi,
Software Development 




 This code experiment uses a Sparkfun Redbot setup for line following. This is a two wheeled robot with 3 optical sensors to detect the line and an I2C accelerometer to sense bumping into objects. The computer is a Sparkfun Redbot Mainboard which is compatible with the Arduino Uno but provides a much different layout and includes a motor driver IC.
This code experiment uses a Sparkfun Redbot setup for line following. This is a two wheeled robot with 3 optical sensors to detect the line and an I2C accelerometer to sense bumping into objects. The computer is a Sparkfun Redbot Mainboard which is compatible with the Arduino Uno but provides a much different layout and includes a motor driver IC.


 My 23″ monitor supports around 18 tabs and my 19″ side monitor about a dozen. Tabs for additional files scroll off to the right. They can be reached using Ctrl-ALT-Right, or through a drop down list on the right, which is cumbersome to use. To add insult, on my Ubuntu system the Ctrl-ALT-Right is used for changing workspaces so cannot be used for changing tabs.
My 23″ monitor supports around 18 tabs and my 19″ side monitor about a dozen. Tabs for additional files scroll off to the right. They can be reached using Ctrl-ALT-Right, or through a drop down list on the right, which is cumbersome to use. To add insult, on my Ubuntu system the Ctrl-ALT-Right is used for changing workspaces so cannot be used for changing tabs.
 Code completion is a simple enhancement that saves keystrokes and prevents errors by adding closing braces, quotes, brackets, parentheses, etc. This reduces errors due to omissions, and helps keep code better organized. (You do put braces around your if-clauses, don’t you? Apple didn’t, which created a
Code completion is a simple enhancement that saves keystrokes and prevents errors by adding closing braces, quotes, brackets, parentheses, etc. This reduces errors due to omissions, and helps keep code better organized. (You do put braces around your if-clauses, don’t you? Apple didn’t, which created a

 [Ben]‘s camera consists of the
[Ben]‘s camera consists of the 





