20
This is an edited version of a longer piece first published on Wevolver.
In recent years, industrial enterprises are accelerating their digital transformation and preparing themselves for the fourth industrial revolution (Industry 4.0). This digitization of production processes enables industrial organizations to implement agile and responsive manufacturing workflows, which rely on flexible Information Technology (IT) systems rather than on conventional Operational Technology (OT). This flexibility facilitates a shift from conventional Made-to-Stock (MTS) manufacturing to novel customizable production models like Made-to-Order (MTO), Configure-to-Order (CTO) and Engineering to Order (ETO).
The implementation of Industry 4.0 compliant production systems hinges on the deployment of Cyber-Physical Systems (CPS) in the manufacturing shop floor. In essence, CPS systems comprise one or several internet-connected devices integrated with other production systems in industrial environments. This is the main reason why Industry 4.0 is also referred to as Industrial Internet of Things (IIoT). IIoT includes the subset of IoT (Internet of Things) systems and applications that are deployed in industrial environments such as the manufacturing, energy, agriculture, and automotive sectors. According to recent market studies, the lion’s share of IoT’s market value will stem from IIoT applications rather than from consumer segments.
The typical structure of IIoT applications is specified in standards-based architectures for industrial systems such as the Reference Architecture of the Industrial Internet Consortium. It comprises a stack of components that includes sensors and IoT devices, IoT middleware platforms, IoT gateways, edge/cloud infrastructures, and analytics applications.
The Power of Embedded Sensors in the Manufacturing Value Chain
IT systems, enterprise applications (e.g., ERP and Manufacturing Execution System (MES)), and industrial networks for production automation have been around for decades. The real game-changer in Industry 4.0 is the expanded use of embedded sensors in the value chain. Embedded sensors transform manufacturing assets into cyber-physical systems and enable many optimizations that were hardly possible a few years ago. Overall, embedded sensors and other IIoT technologies empower increased efficiencies by transforming raw digital data to factory floor insights and automation actions.
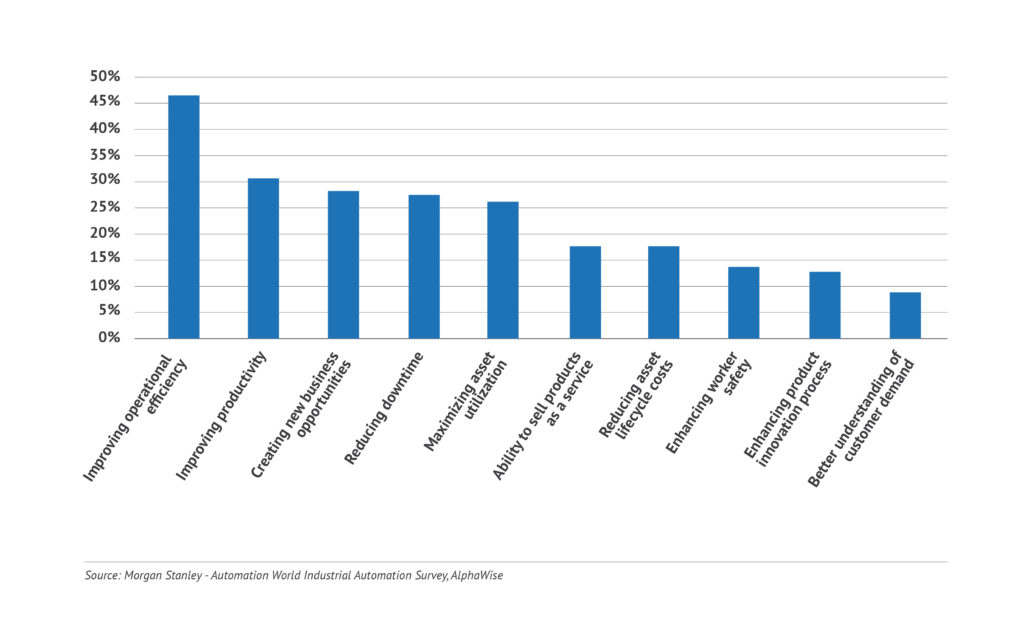
Some of the perceived benefits of IIoT and embedded sensors deployments in production operation include:
- Flexible Production Lines
- Predictive Maintenance
- Quality Management
- Supply Chain Management
- Zero Defects Manufacturing
- Digital Twins
Data analysis options: Edge, Cloud, or combination?
Most IIoT applications include data analytics functionalities such as sensor data analysis based on machine learning techniques. Therefore, they typically collect and process information within cloud computing infrastructures. The latter facilitates access to the required data storage and computing resources. Nevertheless, IIoT deployments in the cloud fall short when it comes to addressing low latency use cases, such as applications involving real-time actuation and control. In such cases, there is a need to execute operations close to the field (i.e., the shopfloor) that cannot tolerate delays for transferring and processing data in the cloud.
To address real-time, low-latency applications, industrial organizations are deploying IIoT applications based on the edge computing paradigm. The latter involves data collection and processing close to the field, within infrastructures like edge clusters (i.e., local cloud infrastructures), IoT gateways, and edge devices. A recent report by Gartner predicts that by 2023 over 50% of enterprise data will be processed at the edge.
Edge computing deployments are best suited for real-time control applications while helping to economize on bandwidth and storage resources. Specifically, data processing within edge devices facilitates the filtering of IoT data streams and enables enterprises to selectively transmit to the cloud “data points of interest” only. Furthermore, edge computing provides better data protection than cloud computing, as data remains within local edge devices rather than being transmitted to cloud data centers outside the manufacturing enterprise. Moreover, edge analytics functions like AI algorithms on edge devices are much more power-efficient than cloud-based analytics.
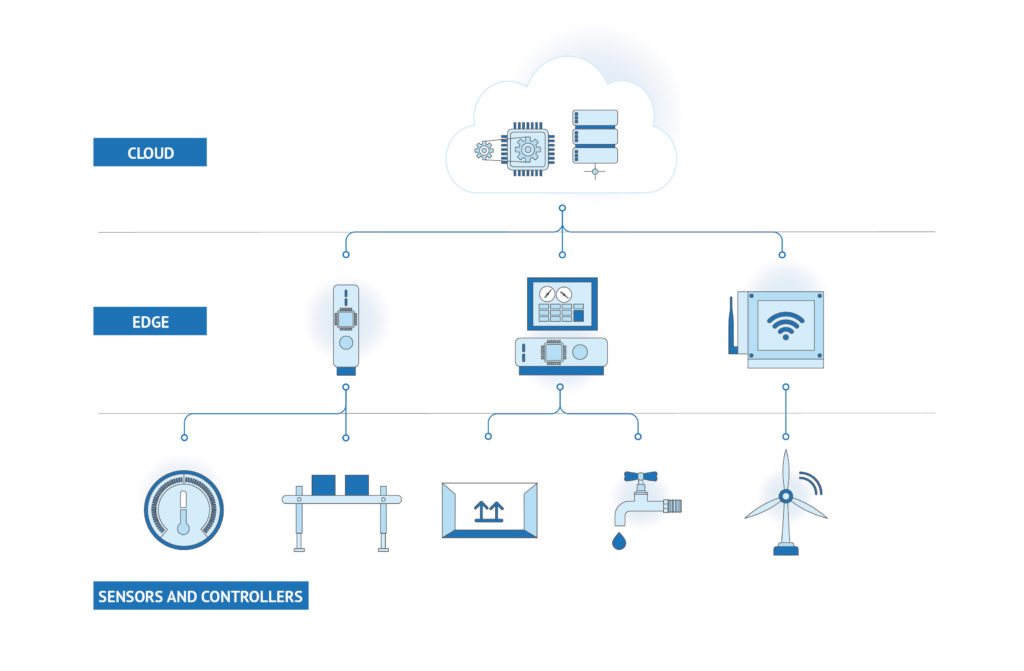
In practice, industrial enterprises employ both cloud computing and edge computing for their IIoT use cases. Specifically, they tend to deploy real-time functions at the edge and data-savvy industrial automation functions on the cloud. There is always an interplay between cloud and edge functions towards achieving the best balance between analytics accuracy, computational efficiency, and optimal use of bandwidth and storage resources. Thus, IIoT applications are usually deployed in the scope of a cloud-edge environment.
Nowadays, there are many ways to implement edge computing and its interactions with cloud infrastructures. Likewise, there are also many options for employing machine learning at the edge of an industrial network, such as federated machine learning techniques or even deployment of machine learning functions in embedded devices. The latter involves a convergence of embedded programming with machine learning, characterized as embedded machine learning or TinyML.
State of the art cloud/edge computing paradigms support varying requirements of IIoT use cases in terms of latency, security, power efficiency, and the number of data points needed for training ML algorithms. Future articles in this series will shed light on the technical architecture and the deployment configurations of some of the above-listed cloud/edge paradigms.
The Scaling of IIoT and the Path towards industry 4.0
Industry 4.0 has been around for over five years, yet we are still quite far from realizing the full potential of embedded sensors and the Industrial IoT. Many enterprises have started their deployment journey by setting up data collection infrastructures and deploying CPS systems and IoT devices on their shop floor. There are also several deployments of operational use cases in areas like asset management, predictive maintenance, and quality control. Nevertheless, many use cases are still in their infancy or limited to pilot deployments in pilot production lines or lab environments. Therefore, there is a need for evolving and scaling up existing deployments to enable industrial enterprises to adopt and fully leverage the fourth industrial revolution.
The scaling up of Industry 4.0 use cases hinges on addressing the following challenges technical and organizational challenges:
- Legacy compliance for brownfield deployments.
- Alleviating data fragmentation in industrial environments.
- Addressing the IoT, BigData, and AI skills gap.
- Ensuring access to pilot lines and experimentation infrastructures.
- Easing IIoT integration end-to-end i.e., from the embedded device to the manufacturing application
- Realizing a cultural shift towards Industry 4.0.
Arduino Pro and Industry 4.0
Driven by these challenges, Arduino has recently created its Arduino Pro solution for Professional Applications. It is an all-in-one IoT platform, which combines:
- Hardware boards for industrial control, robots, and edge AI applications.
- End-to-End secure connectivity solutions for deploying cloud-based applications.
- Advanced development environments that enable low code application development.
- Ease of Implementation and significant community support.
Conclusion
This article has introduced the Industrial Internet of Things, including its main use cases and business value potential for industrial enterprises. It has shed light on how embedded sensors, cloud/edge computing, and Artificial Intelligence provide a sound basis for optimizing production operations in directions that can improve production time, quality, and cost, while at the same time boosting employees’ safety and customers’ satisfaction.
Read the full version of this article, including references used here, at Wevovler.com.
The post Engineer’s guide to Industrial IoT in Industry 4.0 appeared first on Arduino Blog.